Hot 100 --- 搜索二维矩阵 II
本文概览:本文以LeetCode经典题目"搜索二维矩阵 II"为例,从一个看似合理却存在漏洞的初始方案入手,逐步引出将矩阵视作二叉搜索树的巧妙解法,从右上角开始查找,将时间复杂度优化到 O(m+n)
一、题目
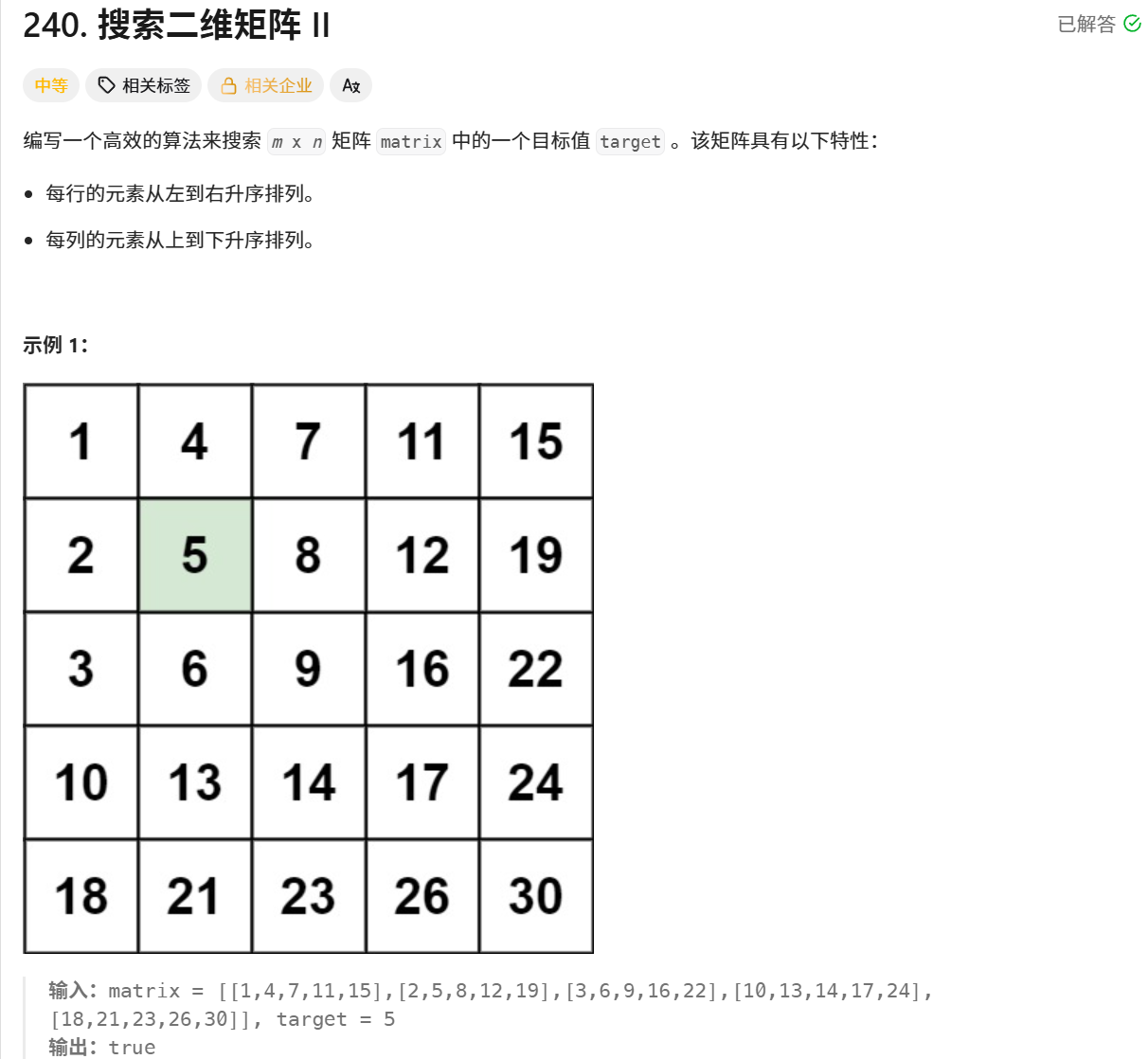
二、题目分析
给定一个 m×n 的矩阵 matrix,每行的元素从左到右升序排列,每列的元素从上到下升序排列。判断目标值 target 是否在矩阵中
目标:在满足"行升序+列升序"的矩阵中高效查找 target
核心问题:如何利用矩阵的两个有序性,避免遍历整个矩阵
思路概览
Java实现代码如下
1 | public boolean searchMatrix(int[][] matrix, int target) { |
思路简要说明
从右上角开始:以
matrix[0][n-1]作为起点二叉搜索树的思想:当前元素大于 target,则 target 一定在左边(
col--);当前元素小于 target,则 target 一定在下边(row++)越界即结束:当行或列越界仍未找到,说明 target 不在矩阵中
三、思路详解
一个看似合理却有漏洞的初始方案
我一开始的做法是:先在第一行搜索,看看 target 应该在哪一列范围内,然后在对应的列上向下查找
这个思路看似利用了矩阵的有序性,但存在致命漏洞——它默认了"每一行的范围在第一行的某一列范围内能定位到",但实际上每一行的元素可能远大于第一行的最大值
反例:
1 | 矩阵: |
如果要查找 target = 6,按上面的思路:
- 第一行最大是 5,6 比 5 还大,定位不到任何一列
- 即使硬要定位到第一行最后一列(5 这一列),从这一列往下找的是 5、10、15,根本找不到 6
问题的根本原因:第一行的范围不能覆盖整个矩阵的范围。当矩阵每行都是连续递增的(行与行之间衔接),第二行起的元素可能完全跳出第一行的范围。所以"先定列再搜列"这个策略会漏掉很多元素
关键思考:能否找到一个起点,使得每次比较都能确定地排除一行或一列,从而不会漏掉任何元素?
把矩阵看成一棵二叉搜索树
观察矩阵的性质:每一行从左到右升序,每一列从上到下升序。也就是说,对任意一个元素 matrix[i][j]:
- 它左边的元素(同一行左侧)一定比它小
- 它下边的元素(同一列下方)一定比它大
这个性质不就是一棵二叉搜索树吗?左小右大!
我们把矩阵向左旋转 45 度,就能直观地看出这棵二叉搜索树的形态:
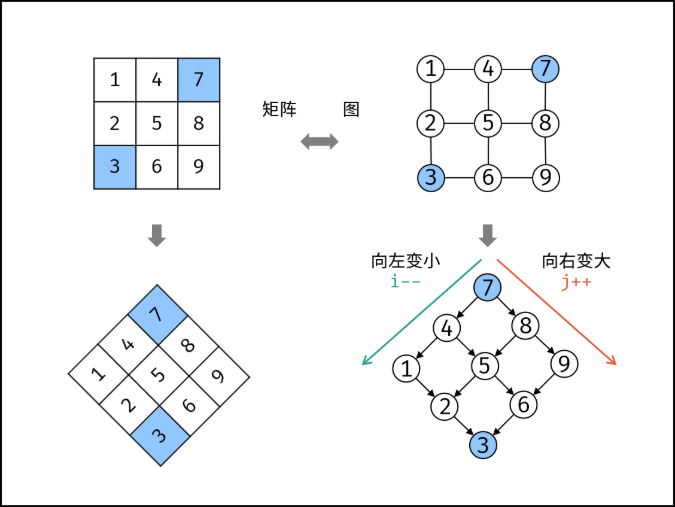
但要注意:起点不能是左上角。如果以左上角作为根节点,那它右边比它大、下边比它大,两个方向都是"变大"的方向,无法形成"左小右大"的二叉搜索树结构,没法做选择
同理,起点也不能是右下角,因为它左边比它小、上边比它小,两个方向都是"变小"的方向,也无法做选择
那应该选哪个角作为起点?
从右上角开始查找
右上角是一个非常巧妙的起点:
- 当前元素左边的元素更小(同一行左侧)
- 当前元素下边的元素更大(同一列下方)
这正好对应二叉搜索树中"左小右大"的性质!把右上角看作根节点,左边就是左子树,下边就是右子树
查找规则:
- 如果
matrix[row][col] == target,找到了,返回 true - 如果
matrix[row][col] > target,说明 target 在当前元素的"左子树"中,col--(左移一列) - 如果
matrix[row][col] < target,说明 target 在当前元素的"右子树"中,row++(下移一行)
每次比较都能确定地排除一整行或一整列,所以不会漏掉任何可能的位置
对称地,左下角也可以作为起点,规律是:左下角左边比它小已被排除(无左边),右边比它大、上边比它小,也满足左小右大的性质
为什么这样不会漏?
每次比较后:
- 如果
matrix[row][col] > target,说明当前元素和它整列下方都比 target 大,可以排除当前列 - 如果
matrix[row][col] < target,说明当前元素和它整行左侧都比 target 小,可以排除当前行
每一步要么排除一整行要么排除一整列,搜索范围每次都在缩小,且不会漏掉任何包含 target 的可能区域
举例说明
以 matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5 为例
初始:row=0, col=4,从右上角 matrix[0][4] = 15 开始
| 步骤 | row | col | matrix[row][col] | 比较 | 操作 |
|---|---|---|---|---|---|
| 1 | 0 | 4 | 15 | 15 > 5 | col-- → col=3 |
| 2 | 0 | 3 | 11 | 11 > 5 | col-- → col=2 |
| 3 | 0 | 2 | 7 | 7 > 5 | col-- → col=1 |
| 4 | 0 | 1 | 4 | 4 < 5 | row++ → row=1 |
| 5 | 1 | 1 | 5 | 5 == 5 | 找到!返回 true |
整个过程从右上角开始,要么左移要么下移,每一步都在缩小搜索范围
- 时间复杂度:O(m+n),最坏情况下从右上角走到左下角,最多 m+n 步
- 空间复杂度:O(1),只用了两个索引变量


